이번 강좌에서는 티스토리 블로그 게시물의 내용을 파싱해보도록 하겠습니다.
해당 강좌에서는 티스토리에서 운영하고 있는 공식 블로그에 올라온 게시물을 파싱해보겠습니다.
사전 정보 수집
티스토리 공식 블로그의 경우에도 비슷하게 모바일 페이지가 존재하기 때문에 모바일 환경에서 파싱을 진행해보도록 하겠습니다.
참고로 일부 티스토리 블로그의 경우 모바일 환경을 따로 제공해주지 않는 경우도 있으니 해당 부분은 직접 확인해보셔야 합니다.
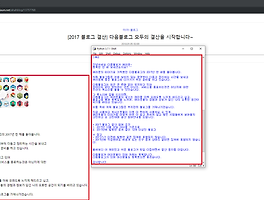
파싱하려고 하는 게시물은 아래와 같습니다.
블로그 통계 후속 업데이트 - '2018년 이전 방문통계' 추가
그리고 이번에도 개발자 도구에 있는 "요소 선택" 기능을 이용해서 필요한 부분을 알아내려고 합니다.
먼저 요소 선택 기능으로 게시물의 첫 번째 줄인 "안녕하세요."를 선택해봅시다.
그러면 태그는 p이고 아무런 속성을 가지고 있지 않은 것을 확인할 수 있습니다.

해당 요소에서 계속 부모로 거슬러 올라가서 본문의 내용을 모두 포함하는 가장 작은 요소를 찾아봅시다.
이를 만족하는 요소는 태그는 div이고 class 속성으로는 blogview_content을 가진다는 것을 알 수 있습니다.

즉 해당 요소에서 p 태그를 뽑아내서 텍스트를 가지고 오고, img 태그를 뽑아내서 이미지를 가지고 오면 됩니다.
이 내용을 기반으로 해서 코드를 작성해보도록 합시다.
구현하기
기존의 방식대로 아래와 같이 코드를 작성하여 실행을 해봅시다.
from bs4 import BeautifulSoup
import requests
def tag_helper(tag):
if tag.name == 'img':
# img tag
return '[IMG]'
elif tag.name == 'p':
# p tag
return tag.get_text()
else:
return ''
def get_content():
url = 'https://notice.tistory.com/m/2469'
req = requests.get(url)
content = req.content
soup = BeautifulSoup(content, 'html.parser')
contents = soup.select_one('div.blogview_content')
result = list(map(tag_helper, contents.find_all(['img', 'p'])))
return result
contents = get_content()
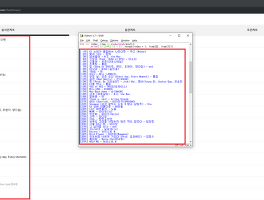
그러면 아래와 같이 AttributeError: 'NoneType' object has no attribute 'find_all' 에러가 나는 것을 볼 수 있습니다.

해당 에러는 contents 부분의 내용을 제대로 찾지 못해서 발생한 에러로 해당 주소의 내용을 제대로 불러오지 못했기 때문이라는 것을 알 수 있습니다.
따라서 아래와 같이 코드를 작성해 실행함으로써 해당 주소의 내용으로 어떤 것을 불러오는지 확인해봅시다.
import requests
url = 'https://notice.tistory.com/m/2469'
req = requests.get(url)
print(req.content.decode('utf-8'))

우리가 원하는 페이지의 내용이 나오는 대신 접근 권한이 없다는 페이지가 나오는 것을 확인할 수 있습니다.
해당 부분은 일부 페이지에서 Python이나 다른 프로그래밍 언어를 이용해서 마구잡이로 데이터를 긁어가는 것을 막기 위해서 사용한 것입니다.
관련 내용은 제가 이전에 포스팅 했던 게시물을 참조해주시면 되겠습니다.
즉 User Agent 부분을 수정하면 해당 방법을 우회할 수 있으며 해당 부분을 반영한 코드는 아래와 같습니다.
현재 User-Agent로 주어진 부분은 19. 01. 26을 기준으로 한 크롬의 User Agent를 의미합니다.
from bs4 import BeautifulSoup
import requests
def tag_helper(tag):
if tag.name == 'img':
# img tag
return '[IMG]'
elif tag.name == 'p':
# p tag
return tag.get_text()
else:
return ''
def get_content():
url = 'https://notice.tistory.com/m/2469'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
req = requests.get(url, headers=headers)
content = req.content
soup = BeautifulSoup(content, 'html.parser')
contents = soup.select_one('div.blogview_content')
result = list(map(tag_helper, contents.find_all(['img', 'p'])))
return result
contents = get_content()
for item in contents:
print(item)
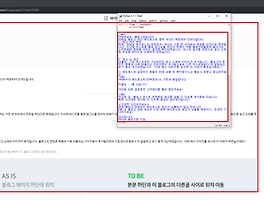
시연 결과
아래 이미지와 같이 해당 게시물에 있는 내용을 가지고 오는 것을 볼 수 있습니다.

더 생각해보기
아래 내용은 직접 생각해서 구현을 해보시기 바라며 해당 내용에 대한 답안은 따로 제공하지 않습니다.
- 이미지 태그 부분을 '[IMG]'가 아니라 해당 이미지의 주소가 나오도록 수정해봅시다.
- 내용 중에 링크가 있는 경우 해당 링크가 가리키는 주소도 같이 출력되도록 수정해봅시다.
- 동영상이 있는 게시물은 동영상에 대한 정보가 나오게끔 코드를 수정해봅시다.
'프로젝트 목록 > ParseWEB' 카테고리의 다른 글
| ParseWEB [1-12] 엠넷 차트 TOP 100 파싱 (0) | 2019.02.06 |
|---|---|
| ParseWEB [1-11] 멜론 차트 TOP 100 파싱 (1) | 2019.02.03 |
| ParseWEB [1-9] 다음 블로그 게시물 파싱 (0) | 2019.01.25 |
| ParseWEB [1-8] 네이버 블로그 게시물 파싱 (0) | 2019.01.24 |
| ParseWEB [1-7] 영풍문고 베스트 셀러 파싱 (0) | 2019.01.23 |